
More and more data is being used in football, although progress is slow. xG is now a fairly accepted method to assess strikers and other attackers. Furthermore, more and more models measuring passing skill are being introduced, like xGChain or other passing ability models. I had my hand at creating a metric which measures ball progression skill roughly a year ago, called xG added. Basically, it’s a model which measures the probability that a possession will become a goal, and praises players which improve these probabilities with their actions. This can be done by passing the ball to a more dangerous location, for instance.
I first blogged about xG added more than a year ago, but have been updating it ever since. If you want to read back what I did previously, have a look at my previous blogs.
Lately, I’ve been rather busy with my Master’s degree, and haven’t had much time to work on football analytics. However, luckily, I was able to continue my work on the xG added model for a research paper I had to write. I can’t tell you how nice it is do work on a hobby and have it count as work for uni. I finished this research paper last month and figured I’d write it up for the blog, be it in a simplified and more readable way.
If you’re not interested in the technical stuff, and want to see the application of the model on last year’s Premier League, feel free to skip the first two paragraphs.
Research paper subject
The previous versions of the model would use all information available about the action, like the action type, end location, whether it was headed, etc. However, it did not take into account information from previous actions. Let’s say we’d want to know what the probability was a goal was going to be scored at the end of an action, the previous model would use the following information (simplified):
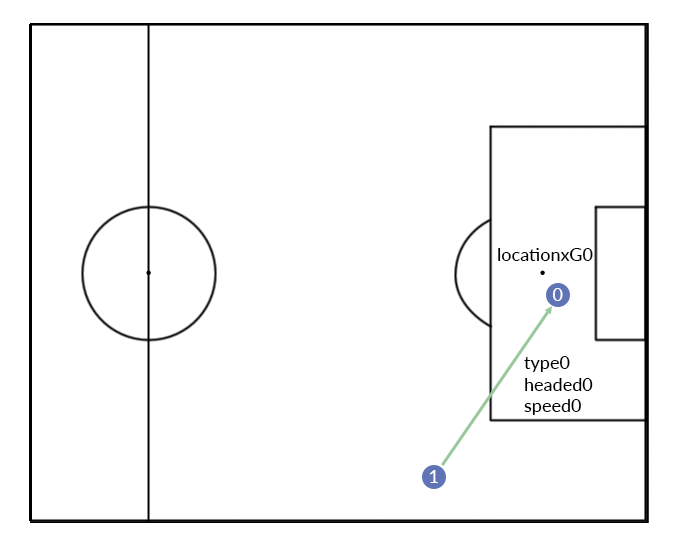
In the above example, 4 variables are included. The type of pass, whether the next action was headed, and the speed of the pass. Furthermore, a location variable is added, called locationxG. This is a value between 0 and 1 describing the probability that a possession becomes a goal if the ball is at that location. I introduced this concept in another blog. It looks somewhat like this:

The purpose of my research paper was to see if including information from actions preceding this action would improve the quality of the model. For instance, if we include the information from one previous action only, we would have the following information:
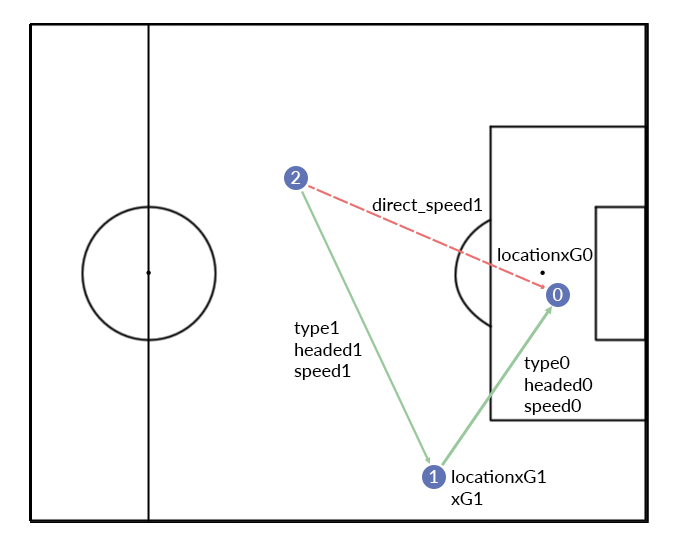
The same variables as before are used, but now for two actions. Furthermore, we look at the direct speed between the start and end location. Finally, I included another variable called xG. This is basically the prediction of the model at the end of the preceding action. For the more experienced people, this means I made the model recurrent.
The image above includes one extra action. In my research I tested models with up to three actions in the past.
The results
As it turns out, the accuracy of the models improve significantly when you add information about the past events. The best model was also the most complex model, the recurrent model with information of the past three actions. Since the best model is the most complex model, it is possible that including even more information from past events might increase the model quality even further.
To get an indication of what variables are important to make a good model, let’s have a look at the top 10 most important variables (d is the amount of steps into the past):
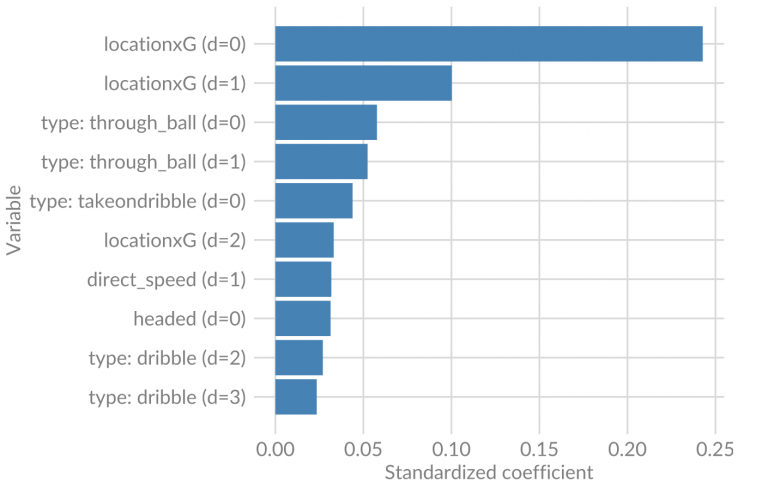
As expected, the end location of the final action is by far the most important variable. However, we see that the previous locations also have a pretty big influence on the possession probability. Other important factors seem to be whether a through ball or dribble was completed recently, which is no surprise. It is also clear that more recent actions have a greater influence on the possession probability than actions that took place longer ago. All of this makes perfect sense, but it is nice to see it from the results as well.
What can we conclude from this (and from my research paper)? Is it significantly better to include past information when assessing possession probabilities? Yes. Is a model that doesn’t use past information bad? No. Even without past information, much of the importation information is already included. Whether to include the information from preceding actions should depend on the amount of time available, and how important accuracy is for the project.
[A very important note is that no tracking data was used here. This means a lot of information is missing due to the limited data. Including tracking data will most likely greatly improve the accuracy of a possession probability model. A simple model including tracking data will probably easily outperform the most complex model used here.]
Let’s scout some players
Using the updated xG added model, we can have a look at the best players in the Premier League for the past season. This gives the following top 15:
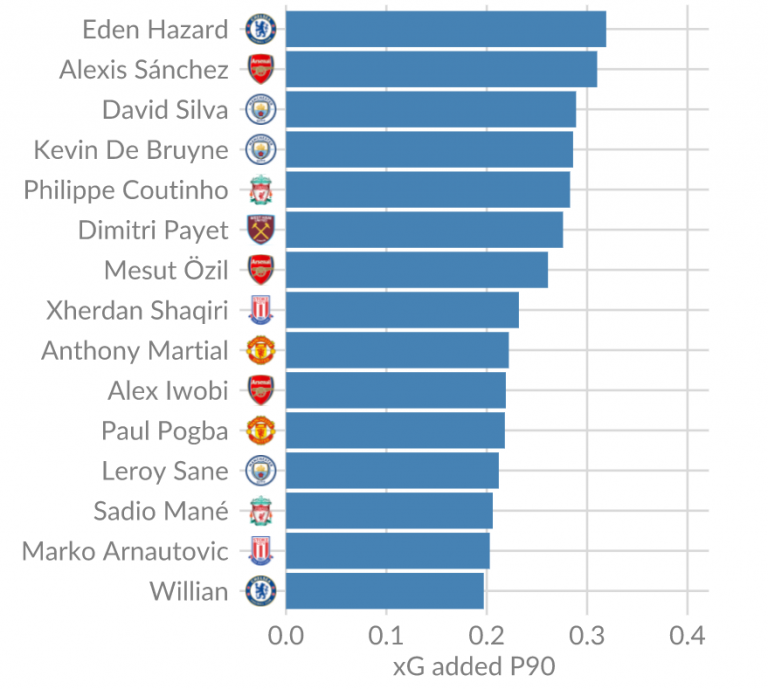
Chelsea all-star Hazard is leading the pack, with the number 1 player in the 15/16 season, Mesut Özil in 7th. The rest of the top 15 consists merely of known elite players and a few prospects. If I were Arsenal or Liverpool, I’d do whatever it takes to try and keep Sánchez and Coutinho, respectively, at the club.
An additional benefit of xG added, is that it can be split into subcategories. For instance, we can look which players performed best with through balls and passing only, or dribbles only. This gives us the following results:
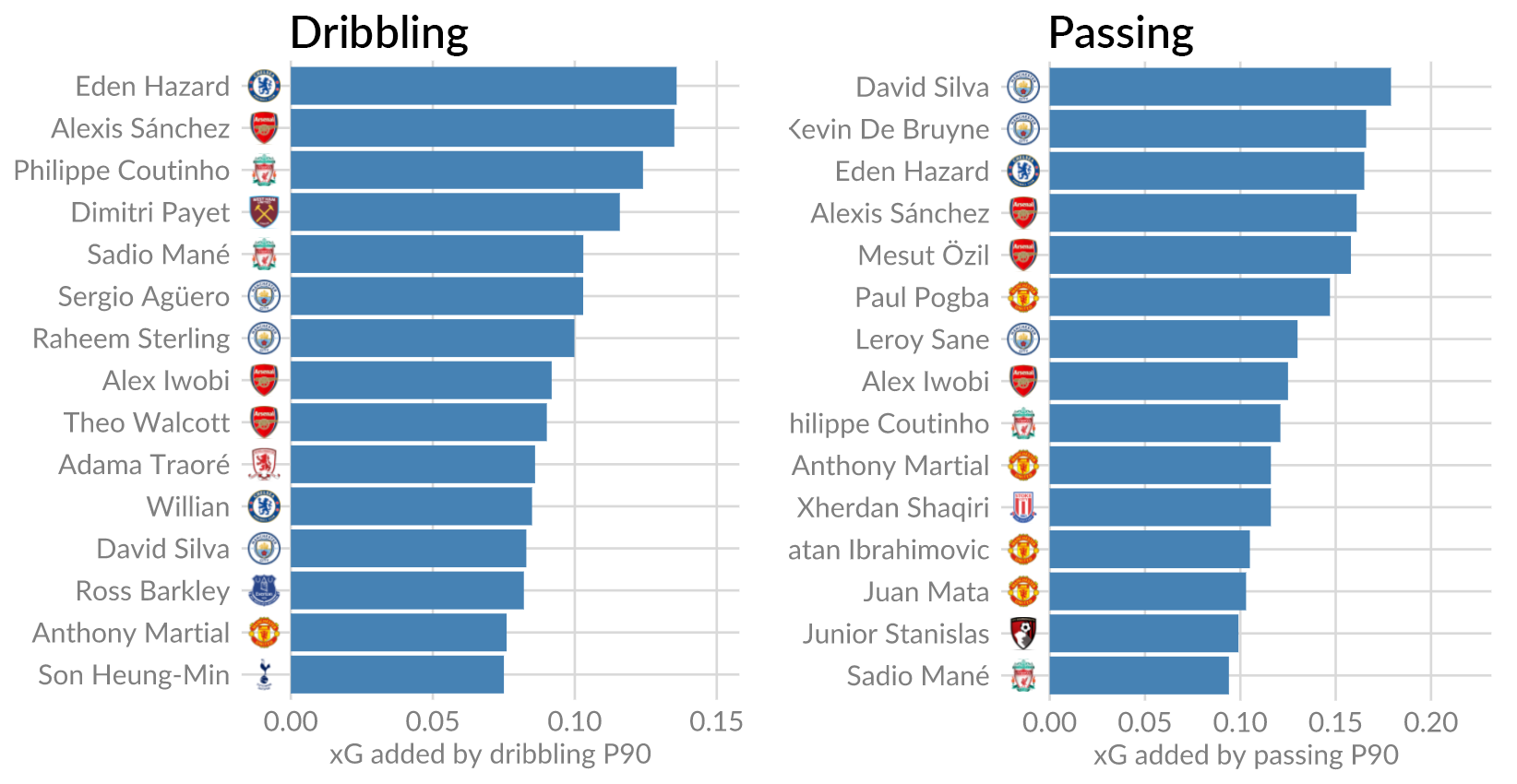
Hazard is, naturally, also leading the pack dribbling wise. New entries are Agüero, Sterling, Walcott and Traoré. On the passing side, David Silva is still destroying defenses at 31. This is also where de Bruyne shines, whereas dribbling-wise he is not among the elite.
These are nice lists, and any club would love to have these players. However, for most clubs they are way too expensive, and possibly too old. Let’s look at players below the age of 25, who don’t play at the Big 6, and who possibly have had less playing time:
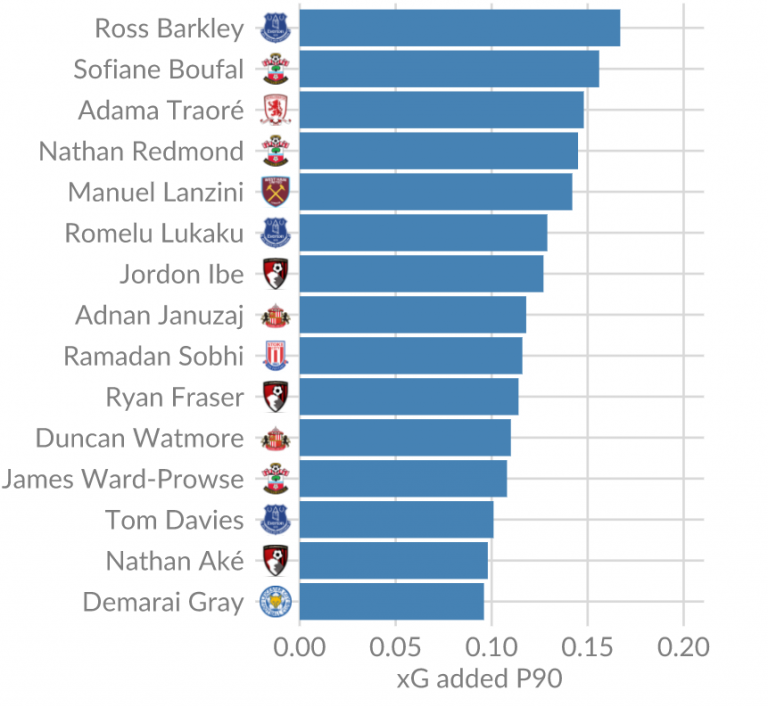
For teams outside of the Big 6 in England, or for teams outside of England with a similar budget, these players might be more payable and still be pretty good. Obviously, Lukaku has additional skills that are not measured here, which makes him unaffordable (except for teams like Manchester United). Players like Traoré and Januzaj might be more feasible options.
Of course, with the Premier League being the most watched league in the world, it is far more likely you’ll find undervalued talent in other, less high-profile, leagues. This is however a nice indication of what is possible using this metric. I feel it performs very well, even with the absence of tracking data.
It is important to note that any metric, including this one, should be followed by video scouting. No single metric will tell you who the best player is to buy, but it will narrow down which players you might want to consider. xG added has one specific use, and should always be used in combination with other metrics.
I’ll end it here. If you have any requests for specific players or teams from this year’s Premier League, send me a message on Twitter.


