
In football analytics the most used advanced metric is ‘Expected Goals’ or ‘xG’, which tries to measure the probability of a shot becoming a goal. It has become so popular even, that when making new metrics, some analysts (like myself) tend to work towards something of the same kind. However, transferring a regular xG model to other areas of research might not always be the best idea, as I will show in this blog.
Back in May, I introduced the metric ‘xG added’, a metric that measures the value of passes. Basically it assigns a ‘danger’ value to the start and end location of a pass. The difference between both values is the ‘xG added’ by the player making the pass. If you want to read a more elaborate explanation, please check this blog.
Assigning the ‘danger’ value in (for instance) my xG added model, can be done in several ways. At first, it seemed easy to use a regular xG model to estimate these ‘danger’ values. However, as @deepxg (if you don’t follow him already now is the time) noted in some feedback he gave me on Twitter, this might not be the most accurate way to do it. An alternative to using a regular xG model, is using a possession-based model.
So what does this mean? Let me explain what they both mean separately and then compare them. At the end I’ll explain why this matters for my model, and other similar models.
Shots-only model
This is your regular xG model. Shooting from distance is less dangerous to the opposition than shooting from close range. Also, shooting from an angle is less dangerous than shooting from right in front of goal. This is the basic concept behind most xG models, and is also visible when you look at conversion rates by location across the last 4 seasons in the Premier League.

The lighter the colour, the bigger the chance you will score if you shoot from that location. Apparently, once, someone scored a goal from their own box. Goalkeeper Begović from Stoke City managed to surprise his colleague from Southampton after only 13 seconds, back in 2013.

Very impressive, but obviously not indicative for the probability a shot from that location will become a goal. That’s why in an xG model, we usually smooth this out, to get something like this:

Much better. It might not be a perfect estimation, but it will do for what I’m trying to illustrate in this blog.
Possession-based model
A possession-based model tries to estimate the probability that, given a certain event, the team with the ball will score within the same possession. Let’s look at an example. Say Team A gets to take a corner kick. The model will try to estimate what fraction of corners ends in the goal within the same possession. This goal could be directly from the corner kick, from a direct header resulting from the corner kick, after a short corner and 35 more passes etc. As long as all the events between the current event and the goal are from Team A, it counts.
For the last 4 Premier League seasons, this will give the following image:
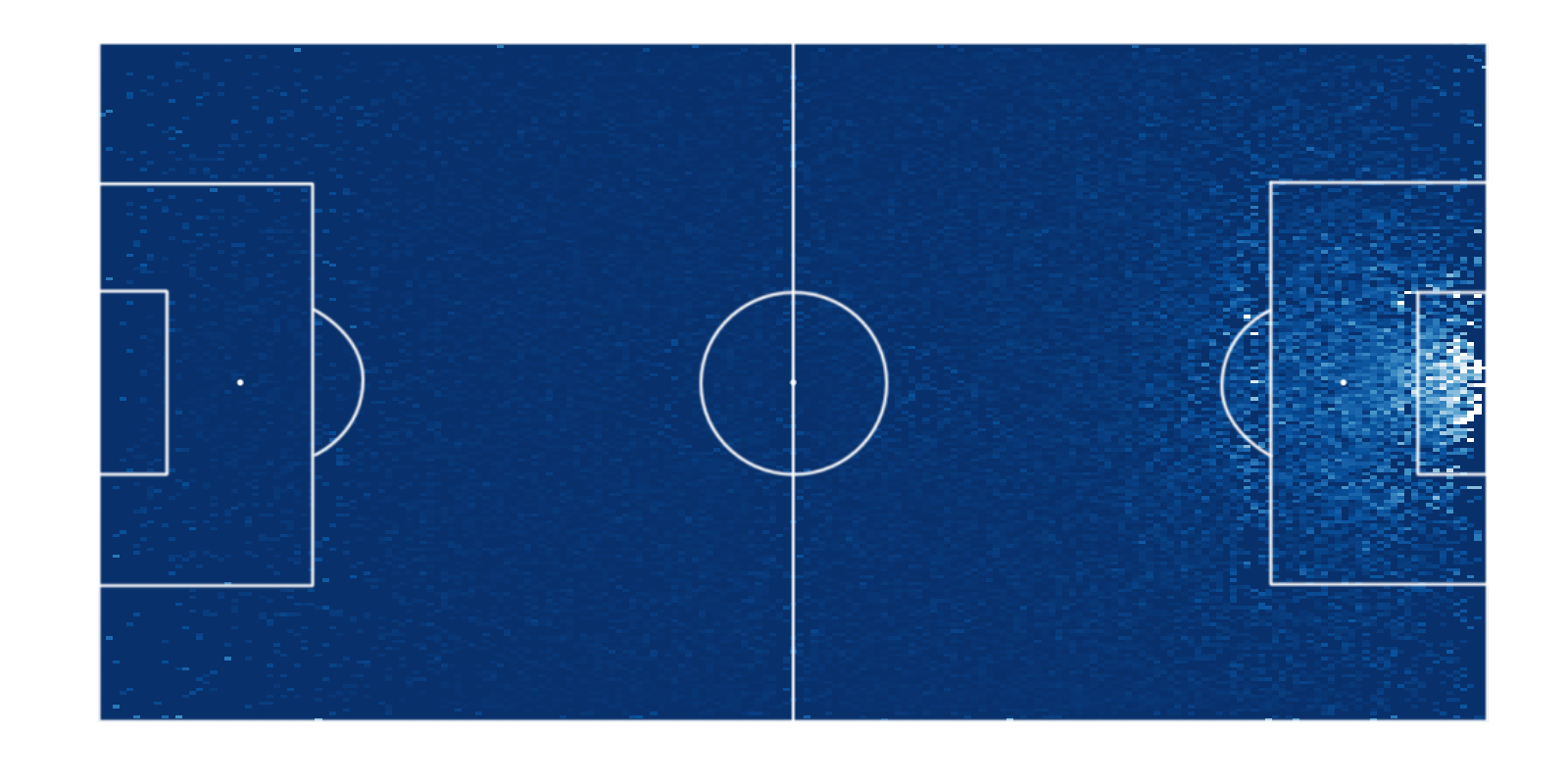
As you can see, this will give higher values on most places on the pitch. This makes sense, as a shot from your own half is unlikely to end up in the goal, whereas a possession in your own half might very well end in a goal within a few moves. Using the same smoothing technique as earlier, we get this:

At this point you might think: mate, that looks exactly like the previous one. Which would be a great assessment. To see what the difference actually is, let’s have a look at a plot of the difference in probabilities:
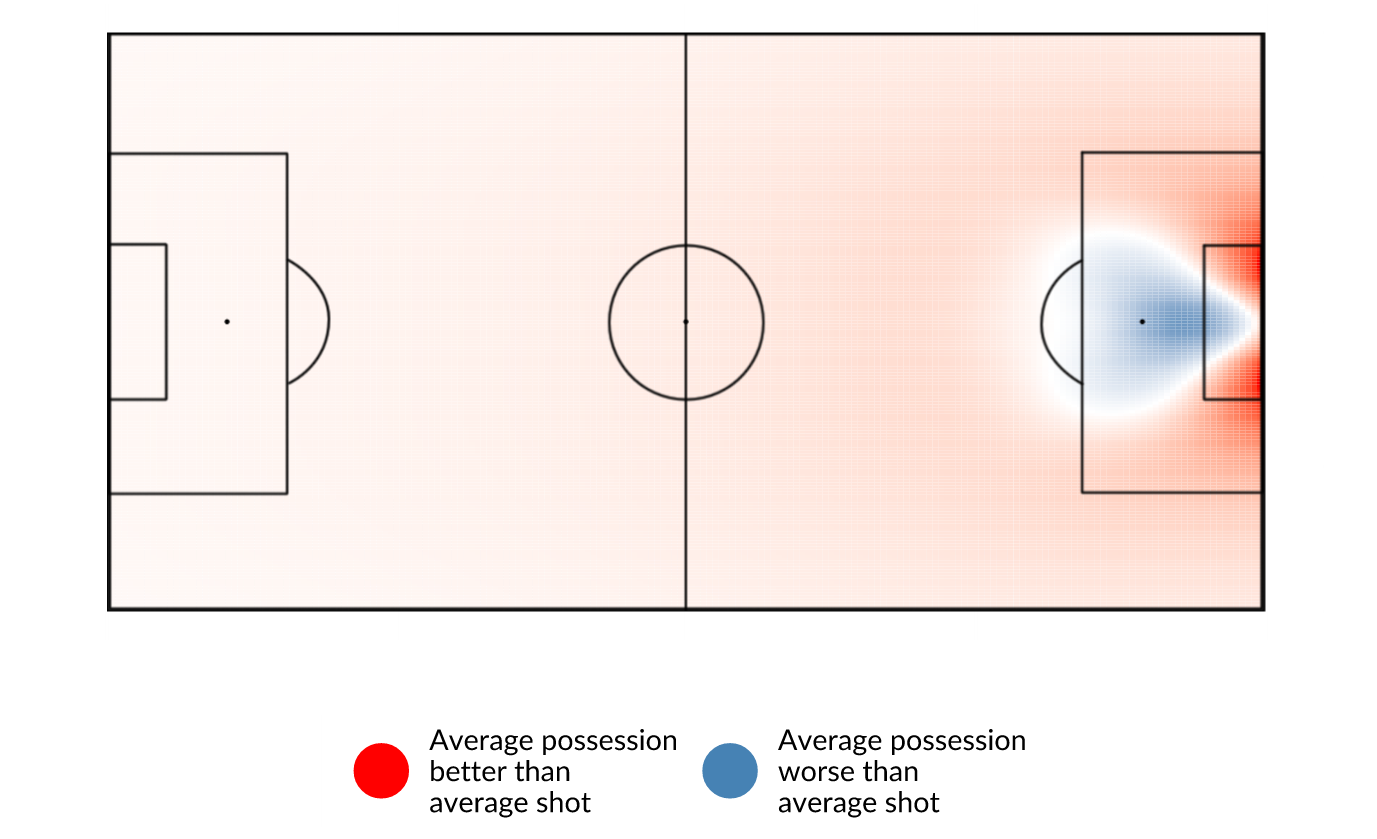
This is where it gets interesting. A blue colour means that a shot from that location is more dangerous than an average possession. A red colour means that a shot from that location is less dangerous than an average possession. In other words, in spots with a red colour it’s probably best to keep playing rather than shooting.
Since this is a very bold statement (pun intended), let me note some things. First of all, the exact rendition of the picture above changes significantly as you change the model you use. However, the overall idea will be the same: a red colour for most of the pitch and from sharp angles, and a blue colour directly in front of goal. Second of all, whether it’s better to shoot or not is highly dependent on other factors than location, such as passing options, opponents location etc. It’s not a good idea to use this map as hard proof of when it’s better to shoot or not, however it can be used to illustrate the intuition behind the decision.
We can see that a possession-based model rates a possession on the back line next to the goal much higher than a regular xG model. We can also see that it rates positions around the box higher, in comparison to positions in the own half. On the other hand, it rates positions right in front of goal a lot lower, since it’s not always possible to shoot if you receive the ball at that location.
So what does this mean for my ‘xG added’ model specifically, but also for other similar models? A few things actually:
- Passes into the blue area get valued less, compared to the old, shots-only model, as not all completed passes into this area can be converted to a shot.
- Passes towards the backline, next to the goal, get valued a lot more. This makes sense as it is still a dangerous location, even if a direct shot is not an option.
- Passes towards the area around the box get valued more. In the previous model this would not be the case, as a shot from 25 meters out is about is dangerous as a shot from 50 meters out. It’s a bit more difficult to see in the picture due to the high values near the goal, but the plot is in general more red in the right half than in the left half.
Apart from the differences, why is a possession-based method better for this kind of model than a regular shots-only method?
In this case the answer is: it makes football sense. After all, even if you complete a pass, your teammate might not always be able to get a shot off. Furthermore, a shot might not be the best option for your teammate. A shot-only model won’t account for these situations whereas a possession-based model will.
Thanks for reading! Keep an eye out for my next blog in a few days, in which I will talk about adding dribbles to the model to see who’s the best dribbler in the Premier League, according to xG added.


