

Expected goals are a difficult metric. Apart from the huge amount of work in takes to create an xG-model, once you’ve got one it’s hard to tell if it’s any good. Most people try to check this by checking if their xG totals for entire seasons are similar to the actual goal totals, mostly using R2. In my latest blog I tried to explain why I think this is a very poor way to evaluate your xG-model. I also hinted at a better way to evaluate an xG-model, something I will explain and apply today. First I’ll explain my methodology and afterwards I’ll apply it to evaluate different xG-models, including a few of the most prominent ones in the community like Michael Caley’s and 11tegen11’s model. Are those models really better than other models? And how close to being perfect are they? If you’re only interested in the results please skip the next paragraph.
Methodology
Let’s first start with the methodology. One of the critiques I had against the full season R2 plots was that a lot of information was lost by summing the entire season together. Therefore I decided to look at single match totals. As far as I know this is the smallest sample at which we look at xG-values, and by looking at single matches rather than seasons we have a lot more data points. The method I will be using to compare the xG-scores to the actual scores is the root-mean-square error percentage (RMSEP). The standard root-mean-squared error is a very simple statistic that measures the differences between your predictions and the actual outcomes. The root-mean-square error percentage (also known as the coefficient of variation of the RMSE) is a normalized version of this that I’ll be using so it’s possible to compare it with my ‘perfect’ model, a theoretical model which I explained in my last blog. The exact formula for the root-mean-square error percentage is:
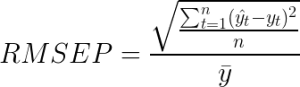
There might be better or more suitable metrics out there but I think this is still reasonably easy and understandable/reproducible, and it’s a theoretically sound metric.
However, the exact value of this metric alone might not give much insight as it’s quite technical. So we’re going to need something to compare the results with. For this purpose, I decided to include two extra ‘models’ in my evaluation, which try to describe the upper and lower bound of performances. For the lower bound (lower is better) I’ll be using the ‘perfect’ model described in my latest blog. As an upper bound I’ll be using the model explained in an infamous Deadspin article, which assigns every shot an xG-value of exactly 0.095. The idea behind this is that if an xG-model can’t do better than that then really what’s the point of making one, so it creates a nice upper bound.
The results are in…
First a short introduction into the models that will be used in this evaluation:
- Nils Mackay, my own model. The start of the methodology can be found here, although I have greatly improved it since.
- Michael Caley (@MC_of_A). Numbers taken from the xG-plots on his Twitter account. Methodology here.
- 11tegen11 (@11tegen11). Methodology here.
- FootballStatistics (@stats4footy), no methodology available.
- @SteMc74. Methodology here.
- Willy Banjo (@bertinbertin). Methodology here.
- SciSports, a Dutch start-up company. (@SciSportsNL). Methodology online soon.
- Ben (@Torvaney). Ben uses a model that only uses x,y location and whether it was a header or not. You can create your own numbers using his model here.
Now for the results:
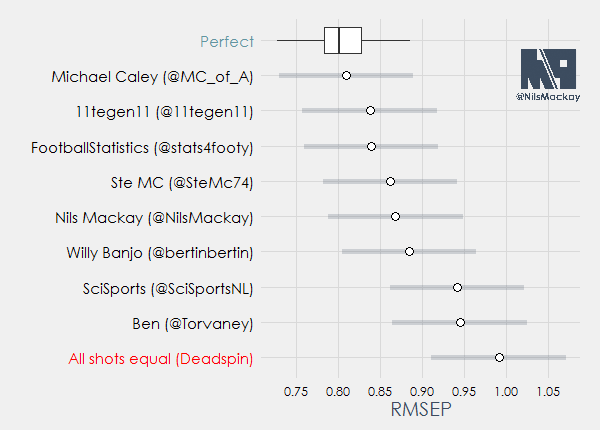
And the winner is…. Michael Caley!
What we see above is the RMSEP for every model (the white dot) for the set of games I used (the first 260 games in this year’s Premier League). On the top you see the ‘perfect’ model, which is a boxplot of 200 simulations I did. Basically, due to variation, a simulation can be relatively more in line with the xG-values, or less. If actual scores are ‘luckier’ or ‘less expected’ than the RMSEP becomes higher, and vice versa. What we can see is that (over a sample of 260 games) the RMSEP of a ‘perfect’ model varies about 0.08 in both directions. To kind of illustrate this ‘confidence interval’ I added the blue lines for all other models, which are basically just the observed value (white dot) plus or minus 0.08. Mind you these are not actual ‘confidence intervals’ as I don’t have those. These confidence intervals have to be seen in comparison with the ‘perfect’ model only though, as different outcomes of games would roughly affect all models similarly. Therefore I think the ranking of the models above is basically what it will be in any sample of 260 games or more.
What’s really surprising is that Michael Caley’s model performs almost as good as the ‘perfect’ model. This indicates that his estimations are really good and don’t have much room for improvement. This is somewhat surprising as the general consensus is that positional data will improve xG-models by a lot. My analysis shows that, although there’s still room for improvement, it won’t really matter that much (for xG-models).
Following by a decent margin we find 11tegen11 in second place and FootballStatistics in third. In fourth and fifth we find @SteMc74 and my own model, closely trailed by Willy Banjo’s model in sixth. In seventh and eighth we find the model by SciSports and Ben’s model. All the way at the back we find the ‘upper bound’, the Deadspin model. As somewhat expected by myself this model performs very poorly on single matches and it’s ‘confidence interval’ doesn’t even touch the worst simulation of the ‘perfect’ model.
So what can we take from here? First of all, even a simple model like Ben’s is a lot better than just counting shots. Second of all, creating a good xG-model can be really hard, but it is not impossible. Caley’s model is living proof that it’s possible to create a model that’s close to a ‘perfect’ model, even without using positional data.
I’ve done some additional analysis that looks at whether the models have certain biases. I feel like this article will get too long if I add it here, so I’ll write something about that in a week or so. Great thanks to FootballStatistics (@stats4footy) for his work in this article. Also great thanks to all the modelers who were so kind to provide data for this analysis.
(NOTE: I decided not to include Paul Riley’s (@footballfactman) model in the analysis. His model looks at xG2, while all the other models in this analysis look at xG1. The main difference between them is that xG2 assigns a value of 0 for blocked shots and shots off target, while xG1 doesn’t look at what happens to a shot. The implications if this is that there are fewer shots to be given a xG-value, which will lead to a smaller RMSEP due to lower variance. I figured comparing his model with the rest would be like comparing apples and pears. For who’s interested, his RMSEP was 0.81, very close but slightly behind Caley’s model.)
(NOTE 2: If you wish to reproduce these results please note that the actual value of the RMSEP for a model varies significantly between different samples. This is due to different amount/quality of shots in the games used. So if you want to see how your own model is doing, you’re going to have to use the first 260 games of the Premier League 15-16, or you’ll have to get data from all modelers for a different sample.)


